研究紹介
述語論理を用いたユーザの意図に忠実なテキスト-画像拡散モデル
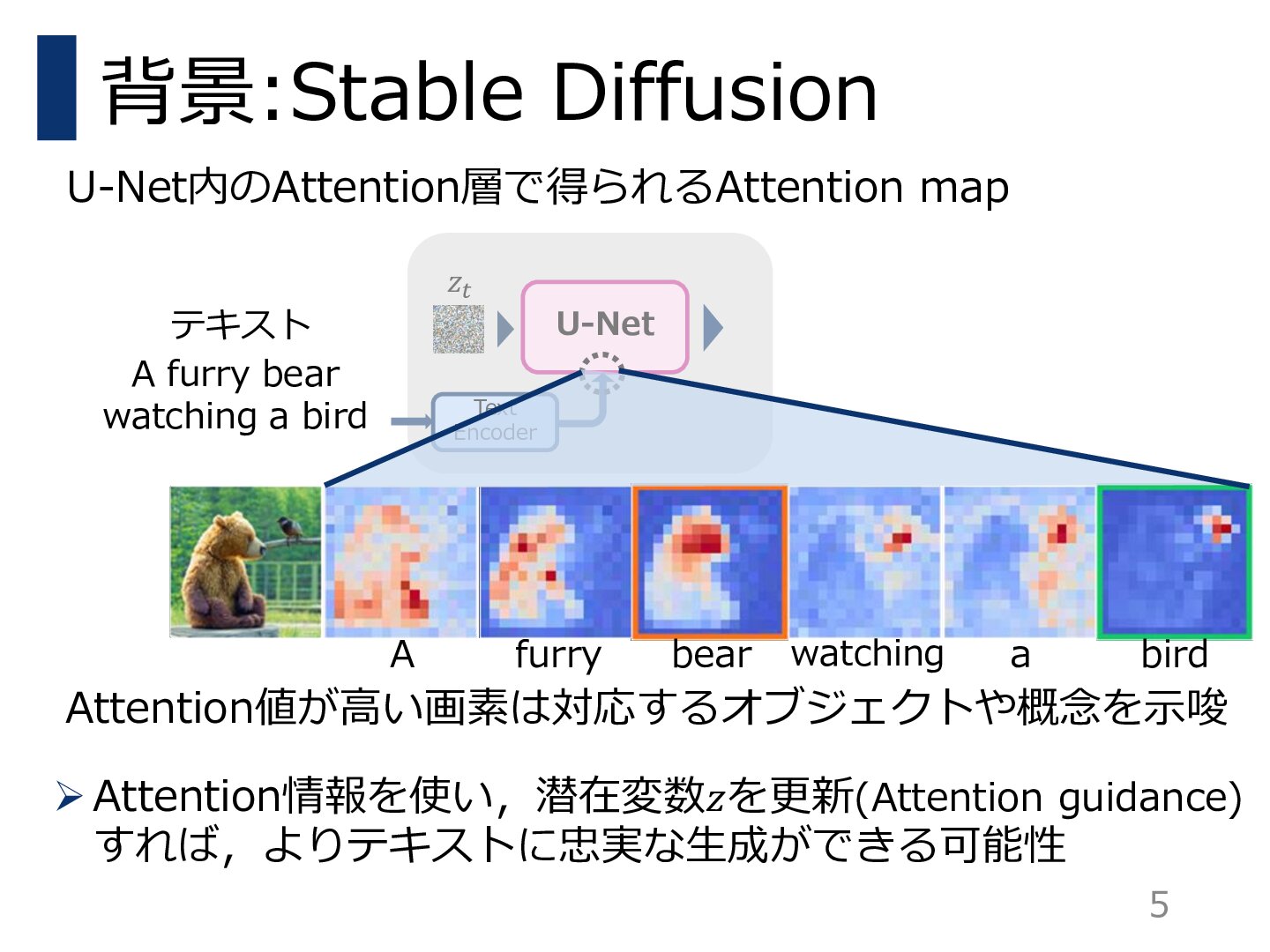
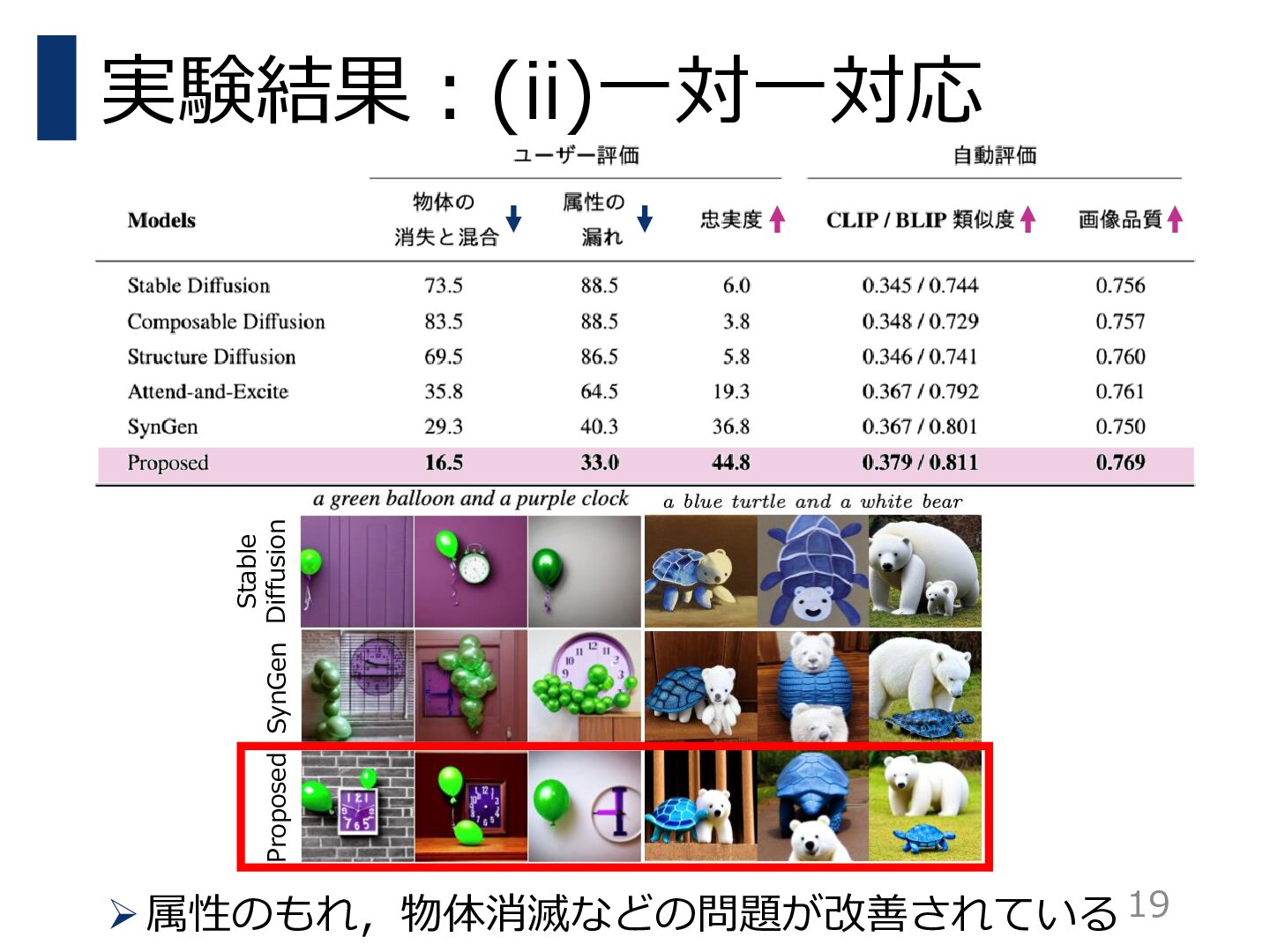
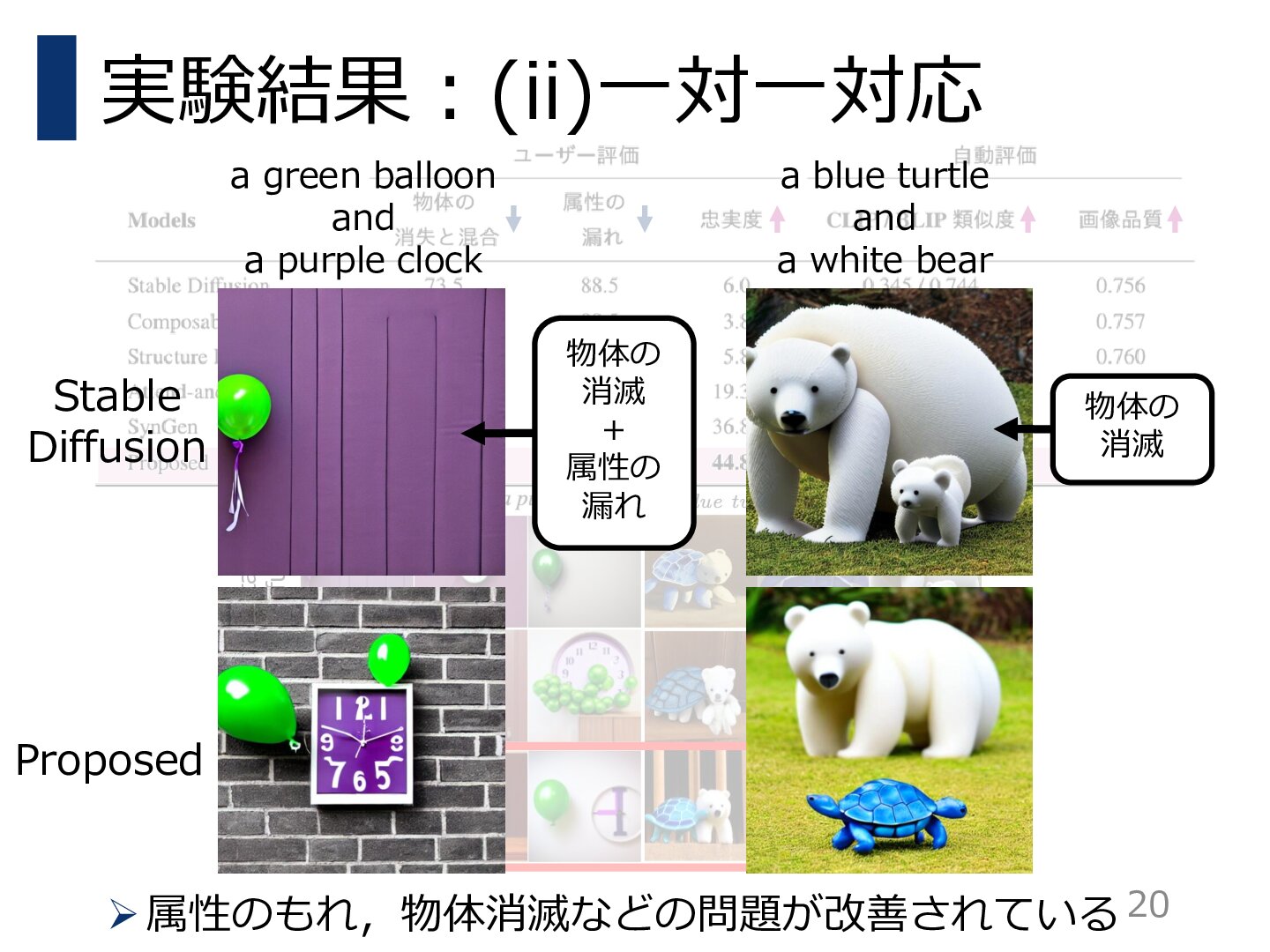
拡散モデルは多様で創造的な画像を高品質に生成することができるが,テキストに基づく生成を行うと,テキストが意図する内容を正確に再現することに失敗することが多い.例えば,指定されたオブジェクトが生成されなかったり,形容詞が意図しないオブジェクトを誤って変更したりすることがある.また,オブジェクト間の所有関係を示す関係が見落とされることも多い.テキストに含まれるユーザの意図は多様であるにもかかわらず,既存の手法ではそのような意図の一部しか解決することができなかった.
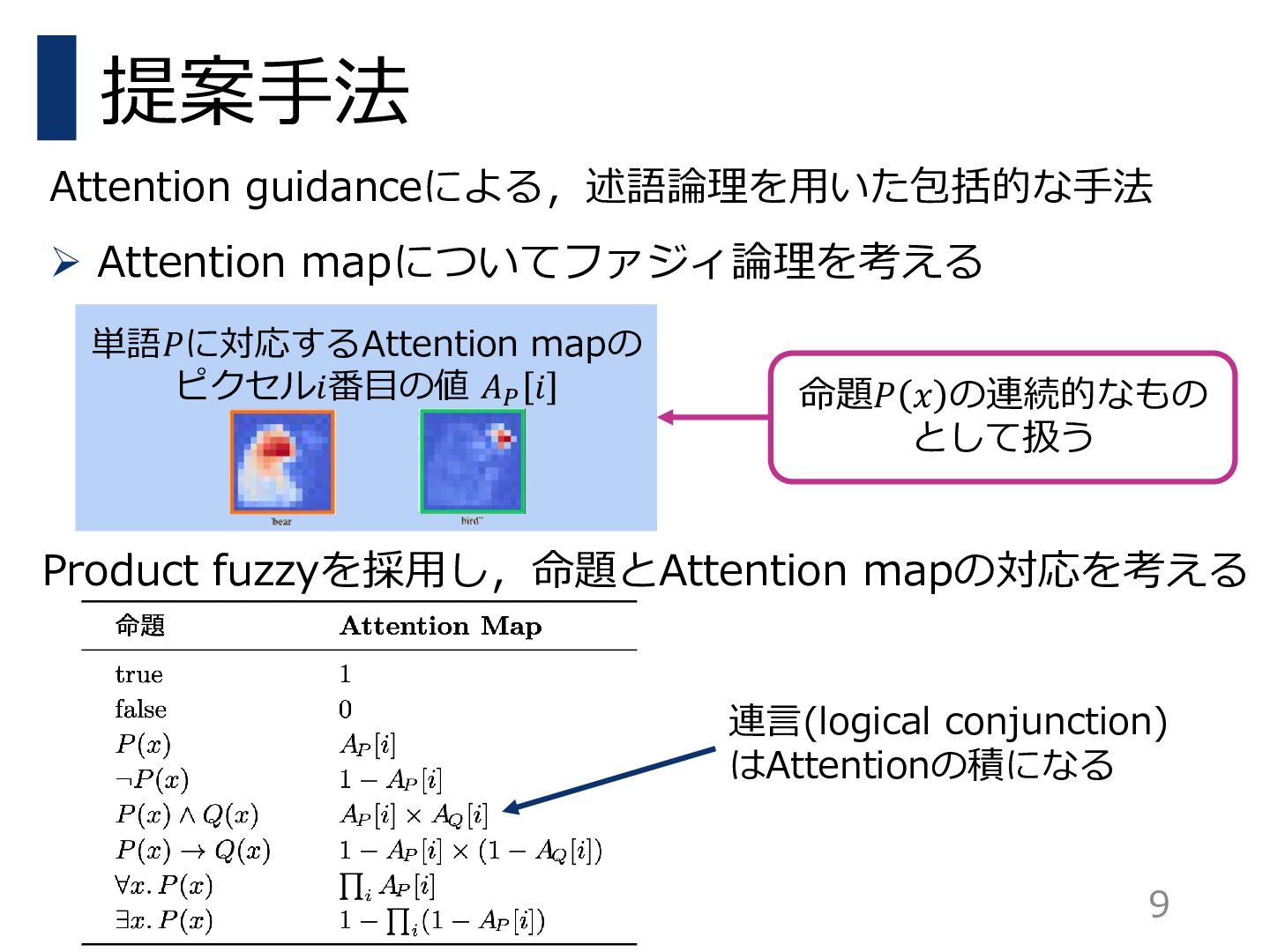
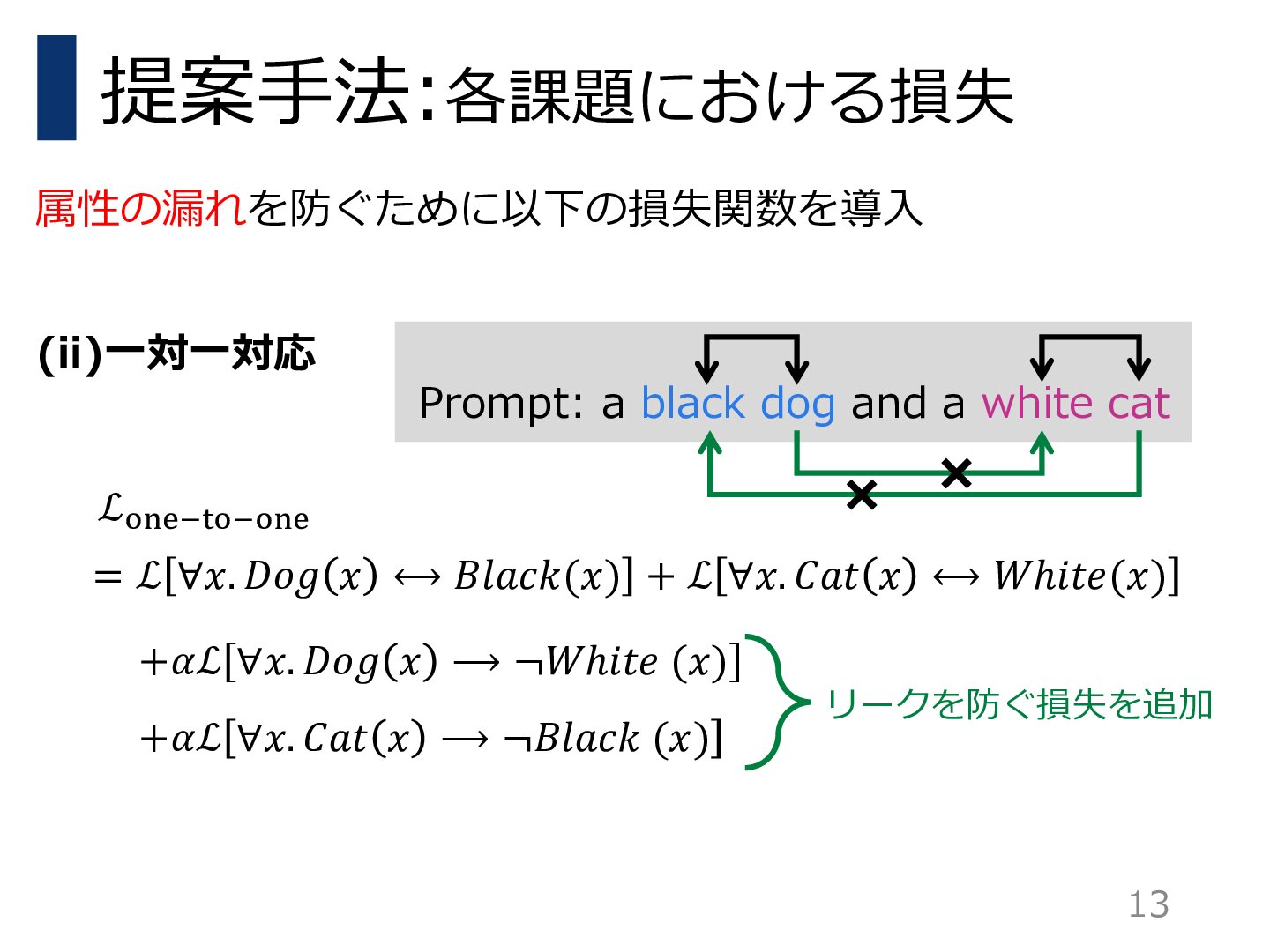
本研究では,ユーザの意図をより効果的かつ統一的に表現できるフレームワークであるPredicated Diffusionを提案する.この手法では,テキストの意図を述語論理を用いた命題として表現する.そして,拡散モデルの内部にあるアテンションマップの強度がファジィ論理に対応しているとみなし,与えられた命題を充足しているかどうかを評価する微分可能な損失関数を設計する.この損失関数を小さくするように生成過程を制約することで,生成された画像が元の意図に忠実であることを保証する.
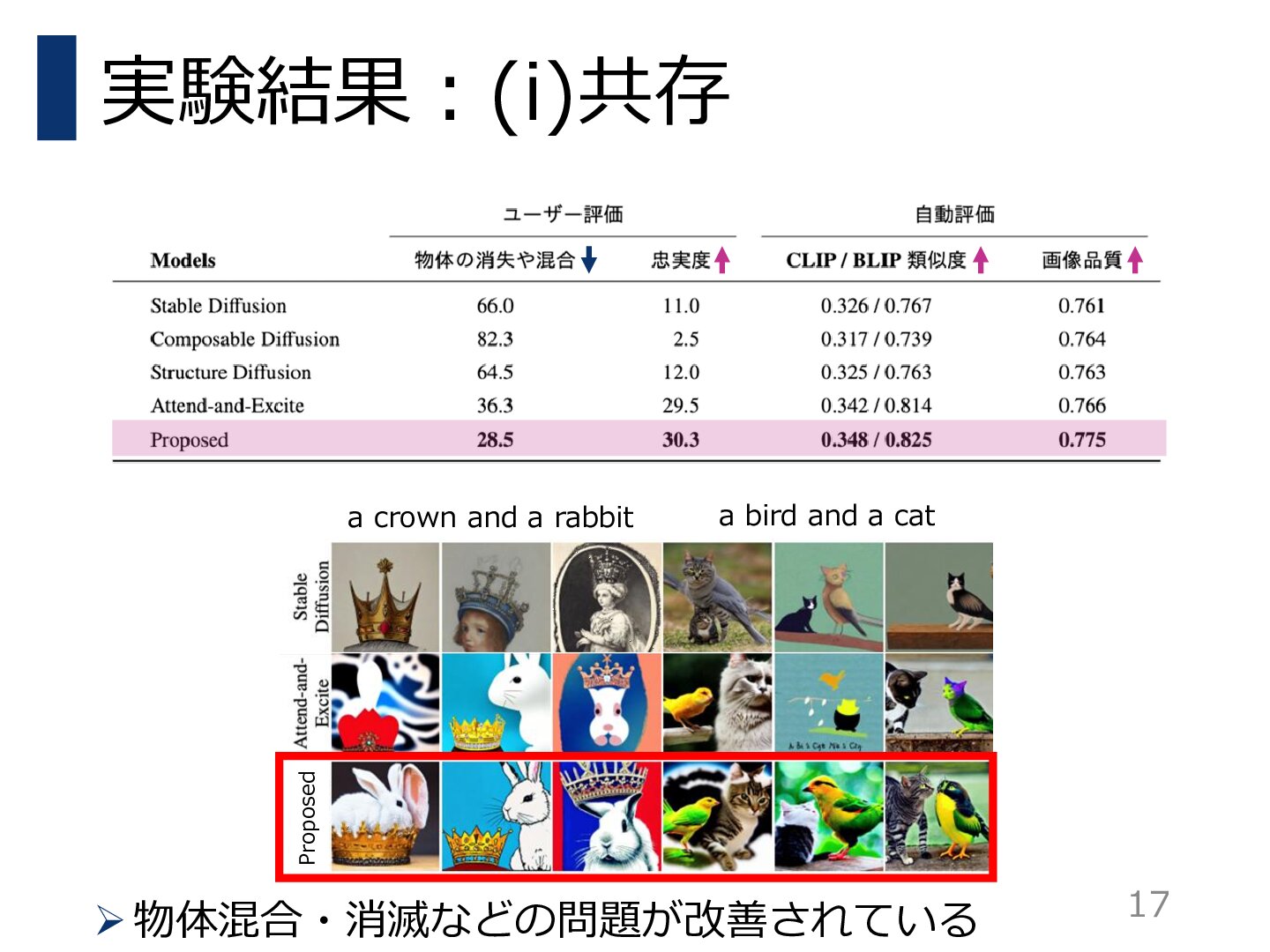
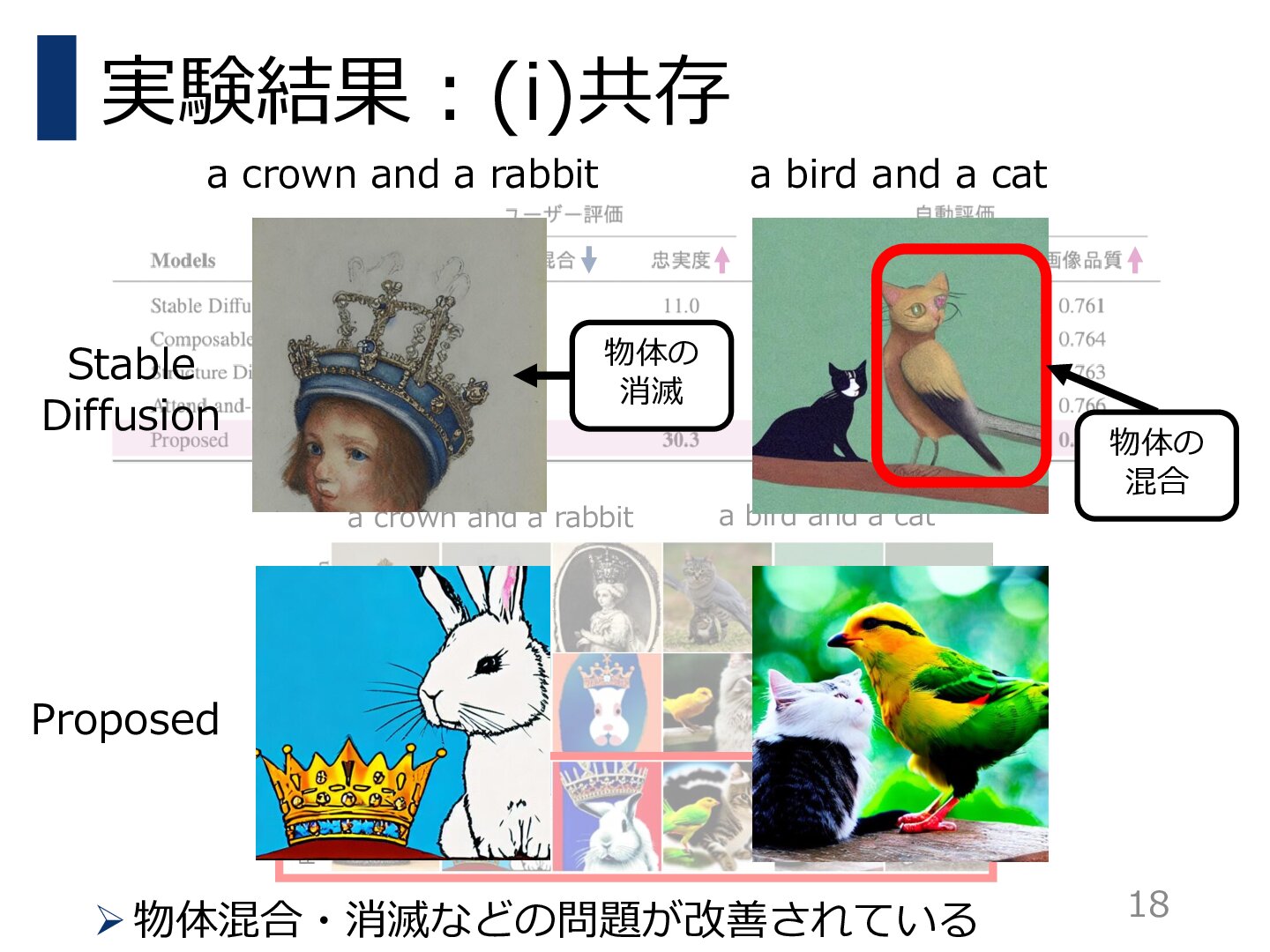
人間の評価者と訓練済み画像テキストモデルによって評価実験を行い,提案手法が高い画像品質を維持しながら,様々なテキストに忠実な画像を生成できることを実証した.
- Kota Sueyoshi and Takashi Matsubara, “Predicated Diffusion: Predicate Logic-Based Attention Guidance for Text-to-Image Diffusion Models,” Proc. of The IEEE/CVF Computer Vision and Pattern Recognition Conference 2024 (CVPR2024), Seattle, Jun. 2024. (highlight) (arXiv)